启动器(Launcher)是一个 Oozie 进程,用于运行工作流(workflow)中的单独一个 Action 的客户端
介绍
启动器是 Oozie 执行模型中非常关键的一部分,下面的架构图向我们展示了 Oozie action 是如何工作的。
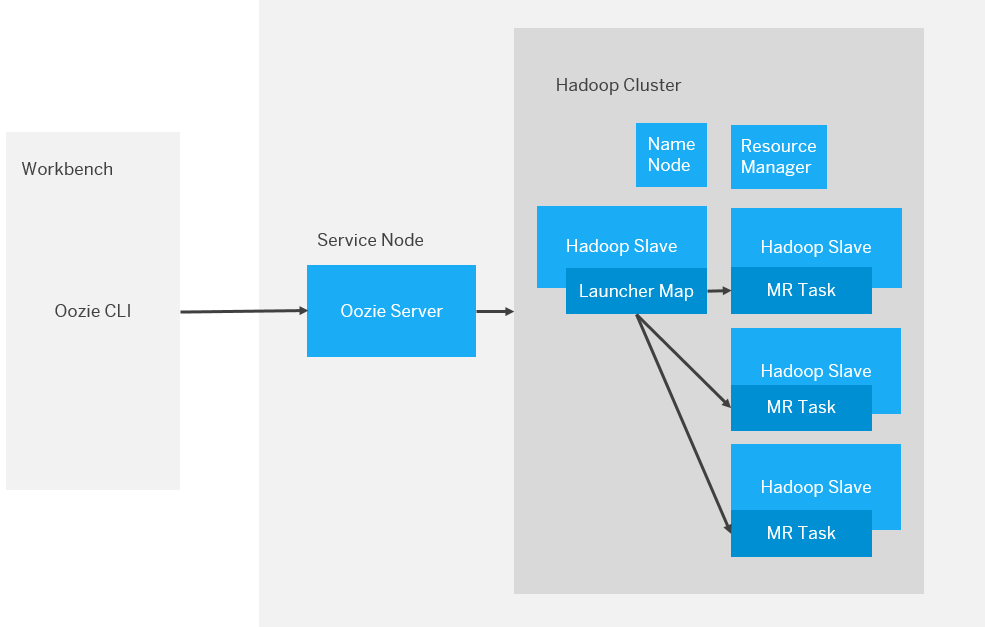
执行模型
Oozie 执行模型与使用者通常启动 Hadoop 作业的方式不同。当使用者从边缘节点(如:workbench)调用 Hadoop、Hive 或者 Pig 的 CLI 工具时,对应的客户端将会运行在该节点上,负责提交作业到 Hadoop 集群并且与 Hadoop 通信。但是,当相同的作业被定义为 Oozie 的工作流中的 Action 并提交,执行流程会变得不同。
假设你在大数据平台通过 Oozie CLI 提交了一个工作流作业,实际上,Oozie 客户端会把这个作业提交到 Oozie server,这个 Oozie server 通常运行在其他节点上,这个节点被称为 Oozie Server 节点或 Service 节点。Oozie Server 负责提交并运行 MapReduce 作业(译者注:Oozie 作业底层会被转换成 MapReduce 作业)到 Hadoop 集群上,不过, Oozie 作业并不会直接使用 Oozie Server 所在节点本地安装的客户端 CLI,而是先提交一个被称为 Launcher job 的 MapReduce 作业到集群上,再由这个 Launcher job 调用对应的 CLI API 启动 Hadoop、Hive 或者 Pig 作业等等。
Oozie 启动器是一个仅包含一个 Mapper 的 MapReduce 作业,运行于 Hadoop 集群上。这个 Map 作业知道其所对应的工作流中某一个 Action 应该执行的操作,然后实际上执行 Action 操作的 Hadoop 作业将会被启动,你可以认为这些随后启动的作业是 Launcher 作业的子作业,而在 Oozie 中这些作业称为异步作业。因此 Oozie 不会在自己的 server 上运行这些 Action,而是将它们通过 Launcher job 放到 Hadoop 集群中运行。
Oozie server 之所以将 Launcher 放到 Hadoop 集群中是为了避免可能出现工作负载过高的影响,同时也可以隔离用户代码和自己的服务。毕竟,Oozie 能访问到 Hadoop 这个如此出色的分布式系统,而且 Hadoop 集群能够满足需要而且做的更好,为什么还要自己实现并且将工作负载放到 Oozie 自己所在的机器呢?
Oozie Action 调试
每一个 Oozie 中的异步 Action 作业都至少会启动两个 Hadoop 作业,一个是 Launcher 启动器,另一个是实际的 Action 作业本身,有时,当 Oozie Action 执行的是包含多个阶段的 Pig 或者 Hive 查询时,会启动更多的 Hadoop 作业。而这些作业,你可以通过 Hadoop 的资源管理器(ResourceManager RM)UI 跟踪到。Launcher 作业的名称会直观的以 “oozie:launcher:” 开头,而 Action 作业通常会包含该作业在 RM 中的名称以及包含 “oozie:action:” 。Action 作业的 stdout 和 stderr 输出都会被重定向到 Launcher 作业的 stdout 和 stderr 输出。当 Action 运行失败并不会导致 Launcher 的失败,同时,当 Launcher 作业启动了实际的 Action 作业并且获得这个子作业的 stdout/stderr 输出后,Launcher 作业的工作完成并且会被标记为运行成功,当你在 Hadoop 中调试 Oozie 作业时,这可能会带来疑惑(译者注:Action 执行失败了,而 Launcher 作业却是运行成功)。
在调试时,至少涉及到两个 Hadoop 作业,你可以通过 Launcher 的 Mapper 日志看到 Action 作业的 stdout/stderr 输出,你也可以通过 Action 作业在 RM 上的日志做进一步的调试,当然,你也可以通过 Oozie 的 UI 获取到所有的这些作业的日志。可能会出现这种情况:Action 或 workflow 在 Oozie UI 中会被标记为 “ERROR” 或 “KILLED”,而 Launcher 作业自身在 Hadoop RM UI 中会被标记为 “SUCCESSDED”,这对于 Oozie 的 Launcher 是很正常的。当你分析 Launcher 作业的日志时,通常可以得到有用的错误堆栈信息协助 Hadoop 作业的调试,而对于有多个阶段的 Hive 或 Pig 查询将会有多个 Hadoop 作业。
启动器的一些问题
在大多数的 Oozie 工作流中,使用者不需要考虑 Oozie 的架构,但是在某些情况下,了解 Oozie Launcher 非常重要。例如,使用者有时在边缘节点运行 Hadoop、Hive 或者 Pig 的 CLI 工具时会出现堆内存空间不足的问题,这是因为在 Hadoop 作业启动前或结束后,这些 CLI 都会在本地进行一些数据处理,这会驱使使用者在执行某些特定查询或代码的时候会通过 HADOOP_HEAPSIZE 或 PIG_HEAPSIZE 调整 CLI 客户端的内存配置。
你可以想象得到,当在 Oozie 工作流中以 Oozie Action 执行相同的查询或代码时,这种方式的配置将不会生效,因为这些作业是由 Launcher Mapper 调用对应的 CLI 启动的,与之前在边缘节点启动方式处于不同的运行环境。想象一下,你的客户端 CLI 工具将随着 Oozie Launcher 在随机的一个 Hadoop 节点中被执行。
幸运的是,Oozie 提供了一种方式让你能够按照自己需要配置 Oozie Launcher。
启动器配置
因为 Oozie Launcher 是一个 MapReduce 作业,因此任何 MapReduce 作业的配置都可以应用到 Launcher 上。但最相关而且有用的往往是内存或队列的配置(mapreduce.map.memory.mb 和 mapreduce.job.queuename),要将设置应用到 Oozie 工作流 Action 的 Launcher 上只需加上 “oozie.launcher” 作为前缀,例如:
1 | oozie.launcher.mapreduce.map.memory.mb |
这个配置会控制 Launcher Mapper 自身的内存或队列设置,与此对应,mapreduce.map.memory.mb 仅仅会影响如 Hadoop、Hive 或 Pig Action 作业底层的 MapReduce 作业。所以当你的工作流中需要执行 Hive 查询,并且需要增加客户端内堆内存大小时(执行 Hive Action 会由 Launcher 调用 Hive CLI 启动),可以在 Ooize Action 定义中配置参数增加 Launcher Mapper 的内存大小。
同样的,“oozie.launcher” 前缀可以应用到其他的配置,如 mapreduce.map.java.opts
启动器队列
队列管理是另一个 Oozie Launcher 需要关注的地方,要知道的是 Oozie Launcher 的 Mapper 会占用 Hadoop 集群中的资源。如果你并行运行多个工作流,或者在一个工作流中并行运行多个 Action,那么将会同时有多个 Launcher,这可能会导致死锁。因为这些 Launcher 可能会消耗完 Yarn 中所有的容器(container),然后等待申请更多的资源去执行实际应该执行的 Action 作业。但是这些 Launcher 将不会申请到更多的资源,因为这些 Launcher 都在互相等待对方释放资源才能够继续运行,这时这个集群将会卡住不动。虽然这种情况不常发生,但是需要了解这么一种可能性。
原文标题:Oozie Launcher and the Execution Model
